皇冠体育(CrownSports)官网 Claude Opus 4.8实测封神!强到离谱,也贵到心痛


新智元报谈

【新智元导读】传闻中的Claude Opus 4.8,性能真实如斯刚劲吗?有东谈主高呼封神,直言这是Opus 5,有东谈主吐槽太拉了,还不如Opus 4.7,手艺大佬也来拆台。是夯爆了如故拉完毕?一文深度识破。
Anthropic王者归来!
深夜,Anthropic全新发布Claude Opus 4.8,一举夺回全球AI王座。
Opus 4.8被定位为一款更刚劲的复杂任务模子,尤其是在编程、智能体任务和万古辰推理方面。
更狠的是,奥秘的Mythos几周之巨匠将面世!

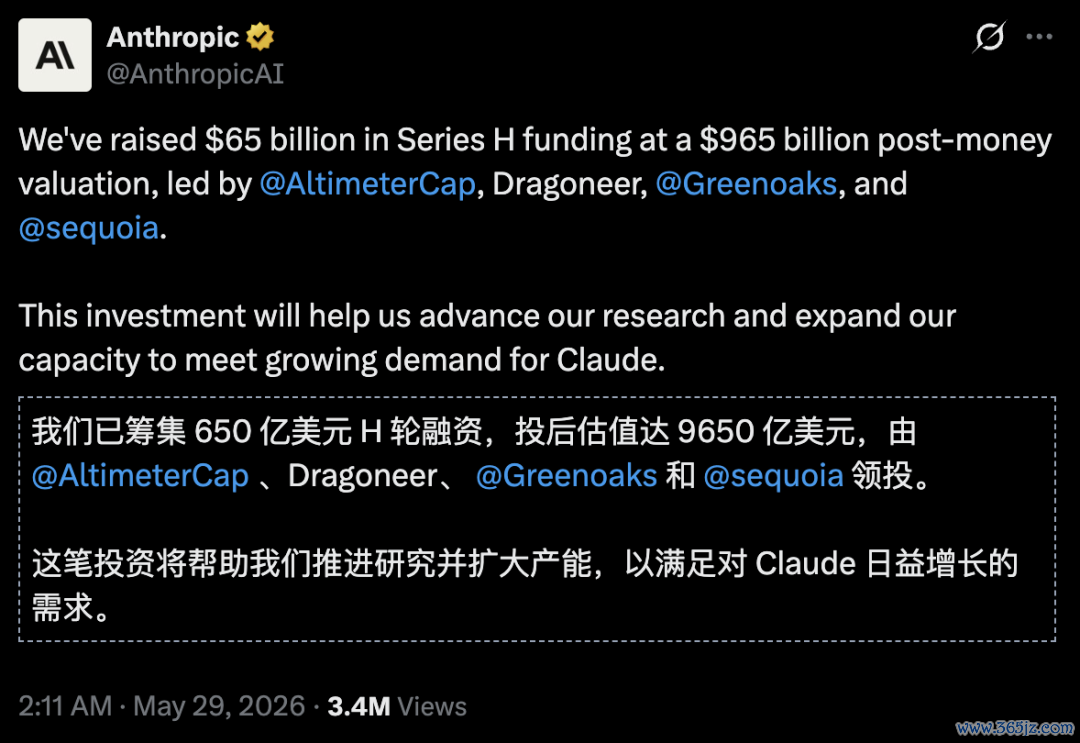
况兼,趁着这鞭策风,Anthropic紧接着告示好音书——
以9650亿好意思元估值完成650亿好意思元融资,卓著62天前OpenAI的8520亿好意思元的估值!
不外,当东谈主们实测事后,通盘科技界短暂分裂成了两个截然有异的阵营。

一方面,是以着名评测媒体Every和部分硬核坐褥力用户为首的「狂热派」。
他们高呼Opus 4.8还是「封神」,致使直言Anthropic此次实在是太低调了,「他们完全不错径直叫它Opus 5,压根不会有东谈主有异议。」
他们直言,Opus 4.8是当前市面上「最全面、最接近东谈主类灵魂与顶尖工程师勾搭体」的模子。

但另一方面,以Ruby on Rails创举东谈主DHH、Redis之父antirez为首的「缔造者老炮」,却在酬酢相聚上公开拆台。
他们认为Opus 4.8的跑分天然险胜老敌手GPT-5.5,但骨子的「编码体感」却依然过时,致使直指Anthropic在基准测试的宣传上犯了关键过错。
一方面,它的「快速格局」、「动态使命流」看起来皆很杀手级,另一方面,桌面端的体验,似乎又很拉垮。
Opus 4.8用起来的真实体感,究竟若何?
这是一次名不副实的挤牙膏,如故一次简直的大跃迁?
接下来,就让咱们揭开全貌!

这不是Opus 4.8,是Opus 5!
领先,是以Every团队为代表的正方。
在长达一周的深度测试后,他们得出了触动论断——这是咱们测试过的最强模子,它简直是个怪物。
致使不错说,它不错被叫作念Opus 5。


暴涨30分的「资深工程师基准」
在极难的「高档工程师基准」测试中,上一代Opus 4.7曾让无数缔造者大失所望,被责问为「难以使用、难以喜爱」。
但Opus 4.8这一次打了一场漂亮的翻身仗。
在「超高强度」格局下,Opus 4.8拿下了63分的高分,不仅比Opus 4.7夸张地暴涨了30分,更是以1分的轻细上风,险胜了一直霸榜的GPT-5.5(62分)。

团队试着让它去绝对重构一个坐褥级别的代码库,效劳Opus 4.8真实寄托了一个能够齐全入手的系统!

效劳说明,Opus 4.8绝不单是是一个补全器用,而是一个能在Repo(代码仓库)级别进行长线念念考的架构师。
79.6分全场最高:击穿「AI感」的最强写手
如若说代码技艺是理科生的狂放,那么写稿技艺则是算计模子EQ的终极顺序。
在Every的写稿基准测试中(涵盖论文、试验邮件、长篇叙事等真实场景),Opus 4.8径直艳压一众模子。

Opus 4.8跑出了79.6的完全高分,远远甩开了自家兄弟Sonnet 4.6(74.5)、老敌手GPT-5.5(73)以及前代Opus 4.7(63)。
「这是一种极度奇妙的体验。」多位创作者响应。Opus 4.8极地面减少了令东谈主不适的「AI味」。

当你给它一份作风指南后,它能特殊精确地师法你的口吻。
它致使展现出了极高的表情学和东谈主际交游瞻念察力,当你试图和它探讨一些深入的表情问题时,它的报酬绝不暧昧,而是会「质疑你的预设框架」,提供丰富、动态且极其具有深度的念念考经过。
100万Token的总揽力,企业级期骗一把过
除了跑分,Opus 4.8在复杂学问使命中的推崇号称怪兽。
它依然保持了100万Token的超大陡立文窗口,这意味着你不错把一整本书的手稿、几周的会议记载,致使一个完整的企业代码库连气儿塞给它。

最让买卖辩论圈战栗的是,在企业级PPT生成测试中,Opus 4.8在Zero-shot的情况下,产出了一份结构显豁、想象合理、叙事逻辑号称齐全的PPT。这是往时通盘模子皆无法作念到的。
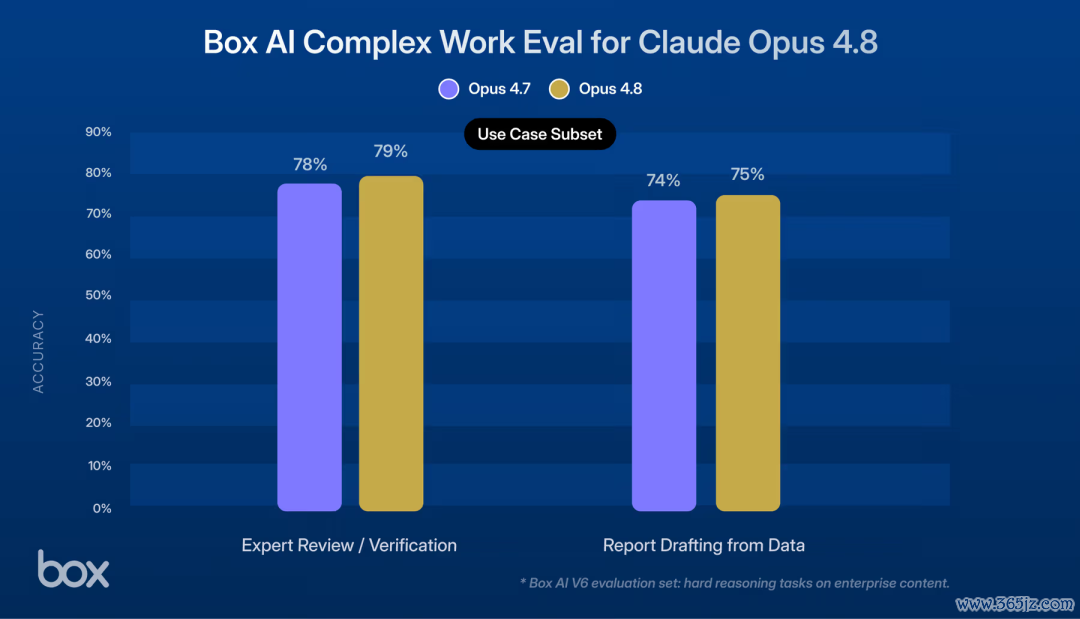
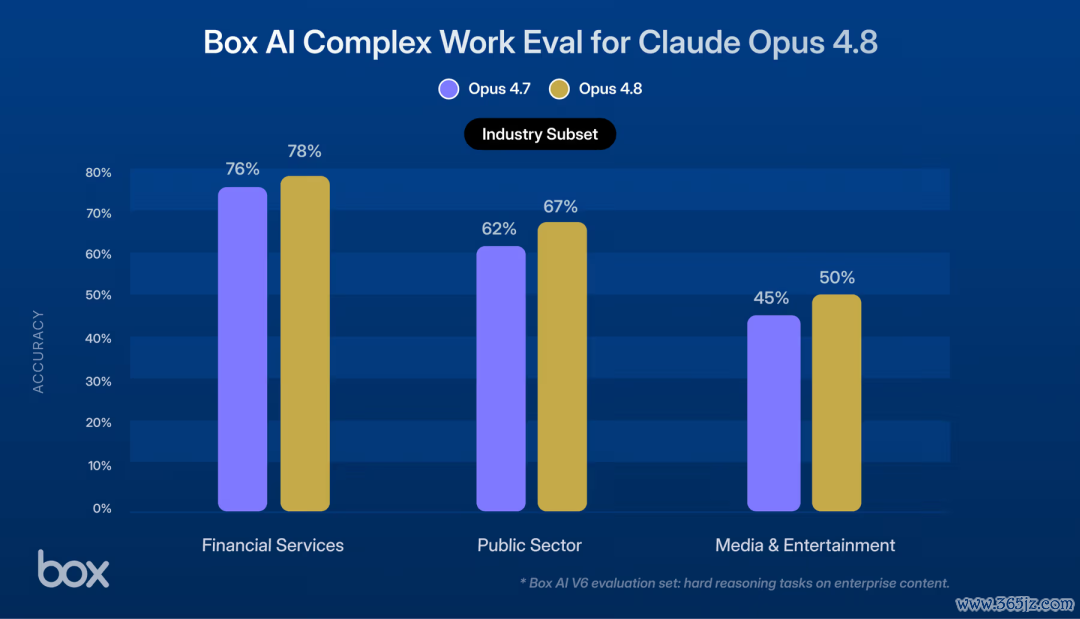
着名云存储处事商Box,也在第一时辰将Opus 4.8接入了其Box AI Agent并在真实企业数据上进行了测试,效劳呈现出碾压态势。

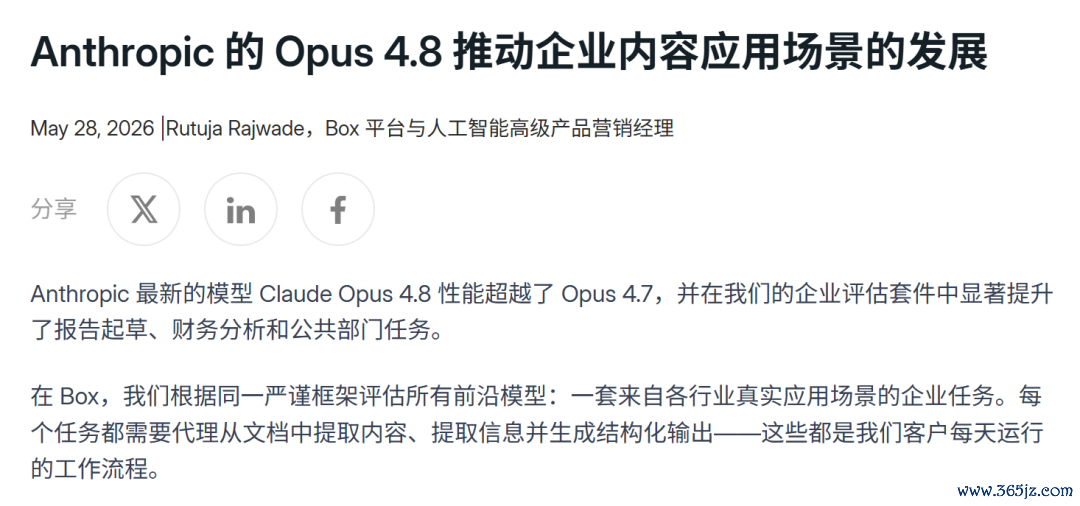
· 讲演草拟:在工业品讲演任务中,4.8得分87%(对比4.7的77%);消费品发布评估任务中,得分高达90%。
· 法律审查:Opus 4.8能够极其精确地抓取合规顺序,找出潜在的条约破绽,并在屡次孤独测试中保持近乎齐全的踏实性。
· 财务数据分析:在复杂的银团贷款与双边贷款结构对比中,从庞大的源文档中索要准确财务运筹帷幄的技艺,比上一代进步了近8个百分点。
沃顿商学院栽种Ethan Mollick的实测更是令东谈主誉不时口。
开云2026世界杯中国官网他把几年前数百份去匿名化的研究文献扔进Claude Code中的Opus 4.8。
效劳,Opus 4.8自主完成了提前淡薄假定、数据清洗、寻找参考文献、进行深度分析、矜重性熟识,临了径直用LaTeX关节排版输出了一篇高度专科的袖珍学术论文!

兴致的是,Mollick栽种用GPT-5.5 Pro手脚这篇论文的「审稿东谈主」,GPT-5.5挑出了一个幻觉过错和几个小问题,随后Opus 4.8坐窝谦恭领受,齐全修正。

大要这等于为什么Every的CEO Dan Shipper欣忭地将Opus 4.8称为我方的「心头好」。
一个不可念念议的软件工程师,同期又是一个领有深度和同理心的近乎东谈主类的作者,二者齐全相融。

沃顿商学院栽种实测的一个Opus 4.8惊艳案例
被群嘲的桌面端与「高才略税」
如斯刚劲的模子,为何莫得在全网酿成完全的碾压之势?
因为Opus 4.8身上包袱着两个千里重的镣铐。

「纵容出遗迹」的代价,是被才略分级欺诈
评测机构很快发现了一个窘态的事实:Opus 4.8的「神级推崇」,不错说是病态地依赖于你给它设定的推理强度(Effort Level)。
在/effort的设定中,只好当档位拉到「Extra-High」时,Opus 4.8才是阿谁得分63的资深工程师;一朝左迁到「High」,它的编码得分会短暂暴跌至42,秒变普通码农。
在写稿上亦然如斯。High档位下的Opus 4.8文笔优雅、逻辑严实;但一朝切到Medium,皇冠体育(CrownSports)官网它就会短暂原形毕露,暴表示AI最厄运的套路化写罪犯习。

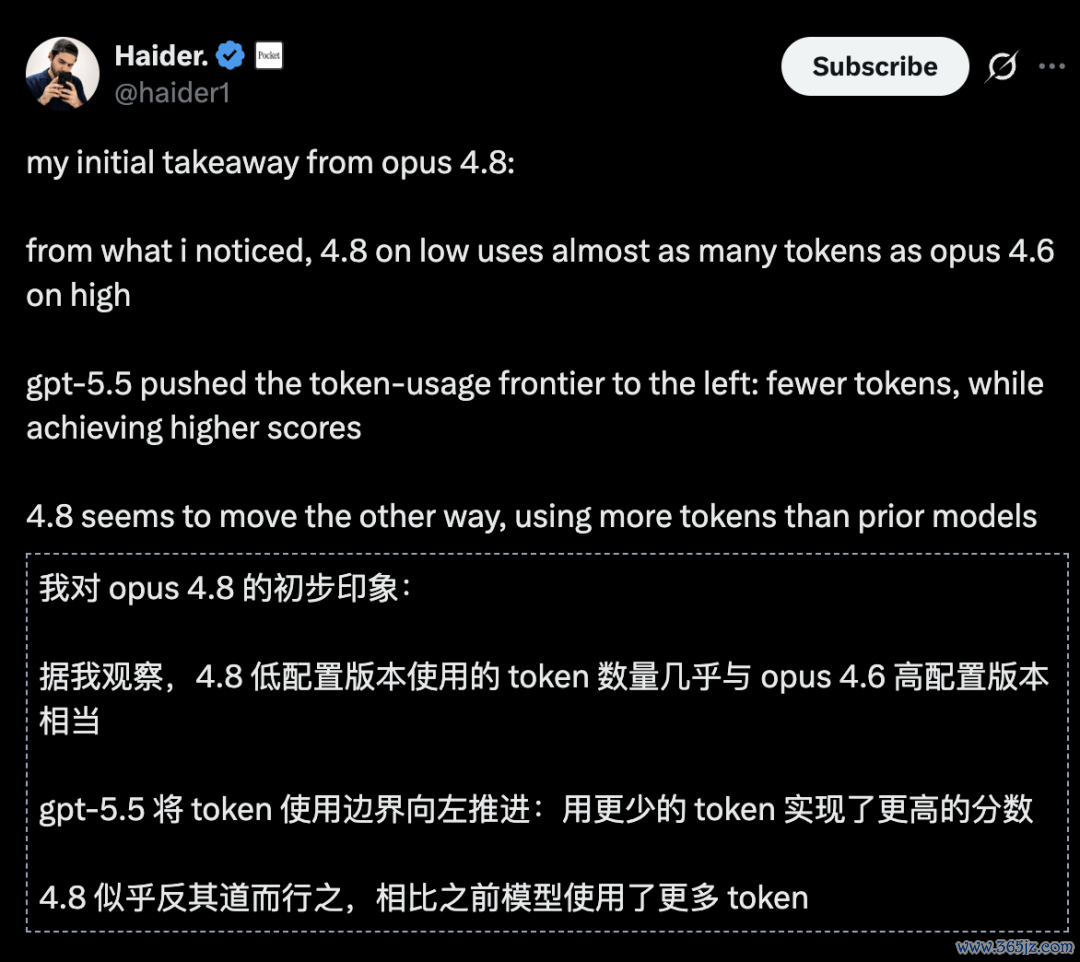
网友Haider明锐地指出了这背后的手艺调谢:
我贯注到了一个景观,4.8在低强度下消费的Token,简直和4.6在高强度下雷同多。
GPT-5.5倾向于用更少的Token拿到更高的分数;而4.8似乎走向了反面,它在用海量的Token堆砌智能。
这就导致了Opus系列一直被诟病的硬伤——Rate Limits。
由于高强度格局相配消费资源,无数订阅了$200/月Max套餐的高端用户响应,在入手复杂Agent任务时,时常几个小时就会撞上额度墙。
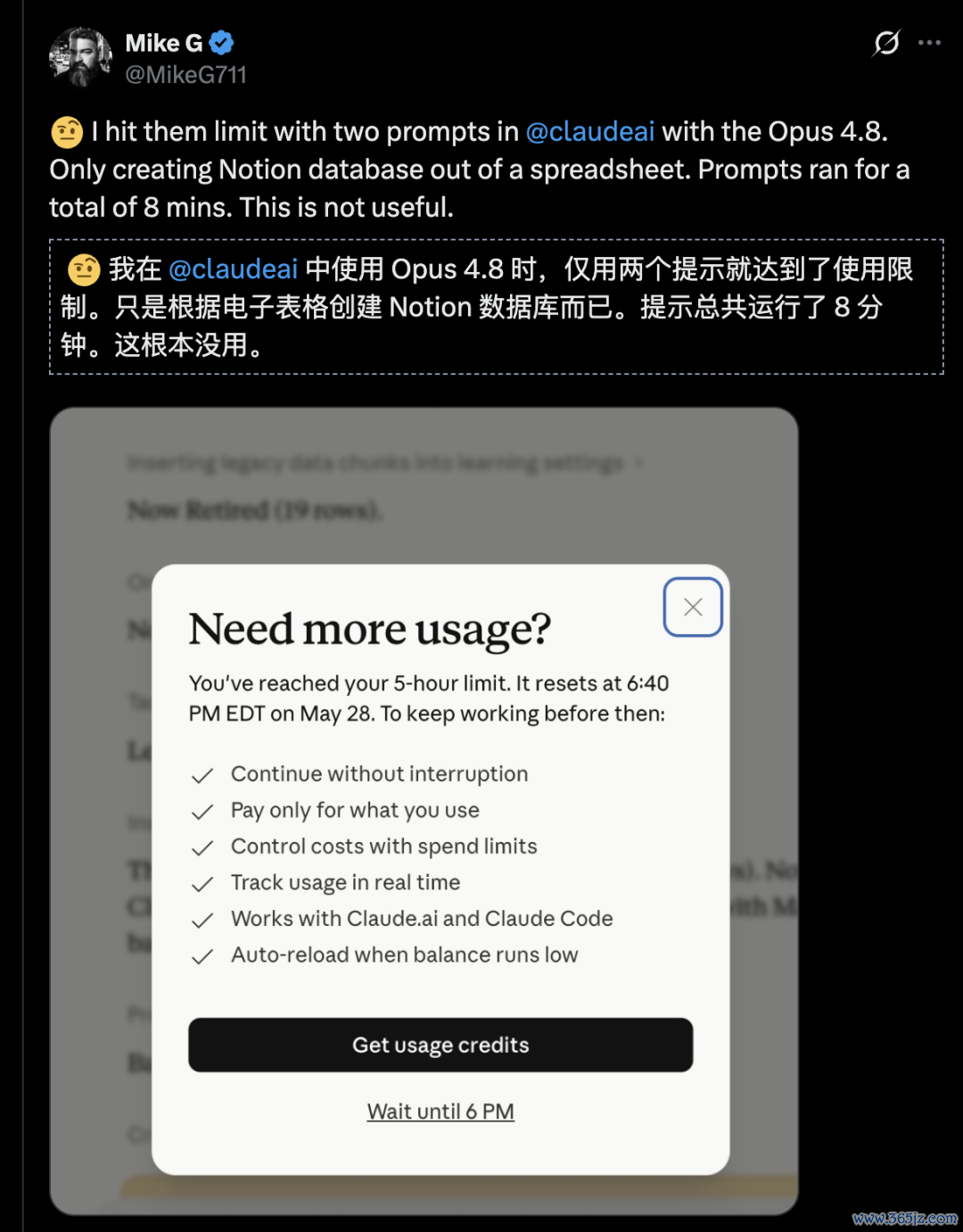
网友BridgeMind直言,我方为了测试聚首烧穿了两个200好意思元的账号。

彰着,相较于OpenAI浩大算力撑持下的宽宏生态,Anthropic显得过于小气了。
混乱的UI想象
如若说模子是引擎,那么客户端期骗等于底盘。而Claude的底盘,正在严重牵扯这台跑车。
多位深度评测者指出,Claude桌面端的想象简直是一场不幸。
Chat、Code、Cowork三个孤独标签页的分割,被责问为「混乱不胜」。
这种割裂的UI想象,被戏称是「带着时辰推移的伤痕和Anthropic里面组织架构图的缩影」。(太亮了)
比较之下,OpenAI的Codex桌面端期骗被公认为是「干净、快速,让东谈主嗅觉这等于将来」。
Opus 4.8的硬核实力如实让好多东谈主想记忆Claude,但厄运的软件交互体验,最终如故让好多东谈主把GPT-5.5+Codex手脚日常主力,只在惩办复杂任务时,才会持着鼻子切回Claude。
极其厄运的「笼子」
大牛工程师Anthony Koeger是这么评价的:最近流行的这句话实在太对了,「一个模子的狠恶,取决于套在它外面的那层壳(A model is only as good as its harness)。」
而Opus此次有些拉跨。
是对于「本分」的营销,如故「跑分罗网」下的计策失实?
伴跟着Opus 4.8的发布,全网也爆发了一场对于大模子「跑分道理道理的空前舌战。
这场争论的导火索,等于一张Anthropic我方制作的官方发布图。
眼尖的网友Aakash Gupta发现了一个极不寻常的细节——
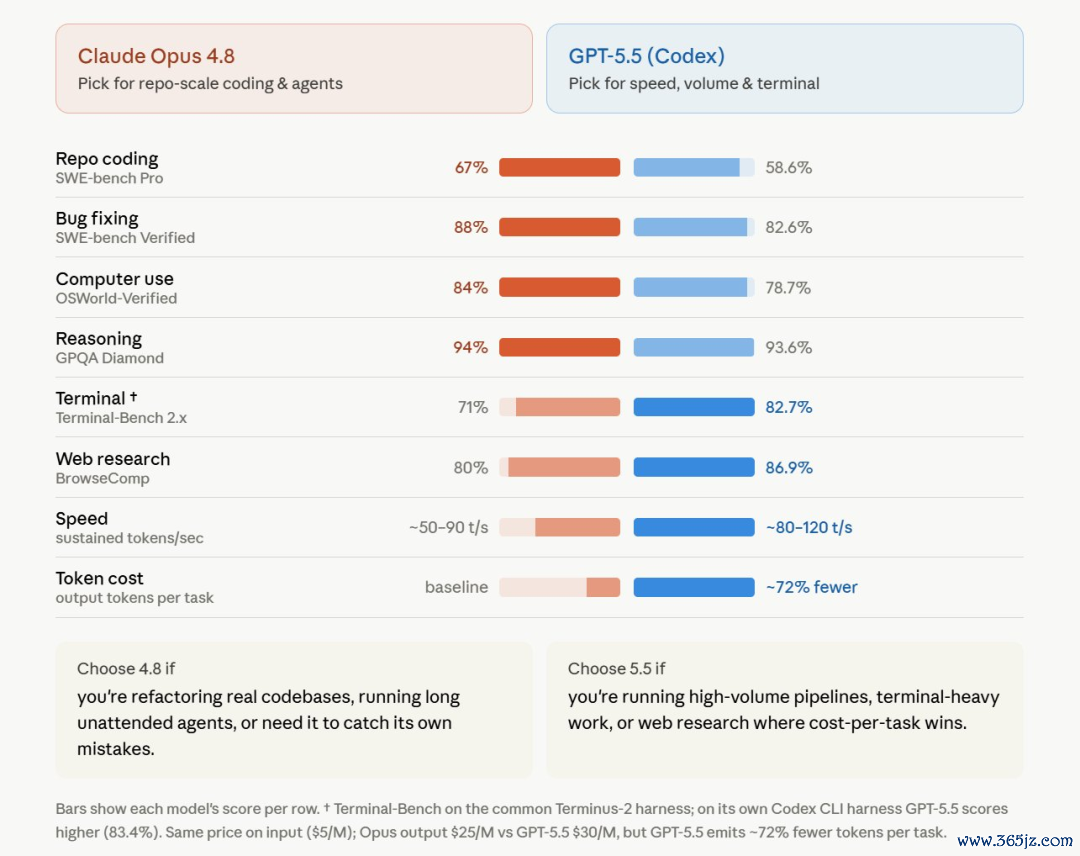
在Anthropic发布的各模子技艺对比图中,在TerminalCoding这一项上,GPT-5.5的收成是78.2%,而Opus 4.8只好74.6%。

平时情况下,任何一家大厂的公关部,皆会把输掉的测试项暗暗从PPT上抹去。
但Anthropic莫得,他们不仅把失败留在了图表上,致使还主动把GPT-5.5那代表到手的78.2%作念了加粗惩办。
Aakash对此大加支柱,认为这高慢出Opus4.8的中枢卖点——本分。
在大型Agent任务中,模子最上流、最致命的失败格局,等于「过度自信」。
而Opus 4.8最大的隐性升级,等于它更首肯承认我方不细目。官方数据高慢,4.8在代码中留住舛错却不声张的概率,比4.7缩小了惊东谈主的4倍。
此次,Anthropic卖的不是跑分,而是本分。

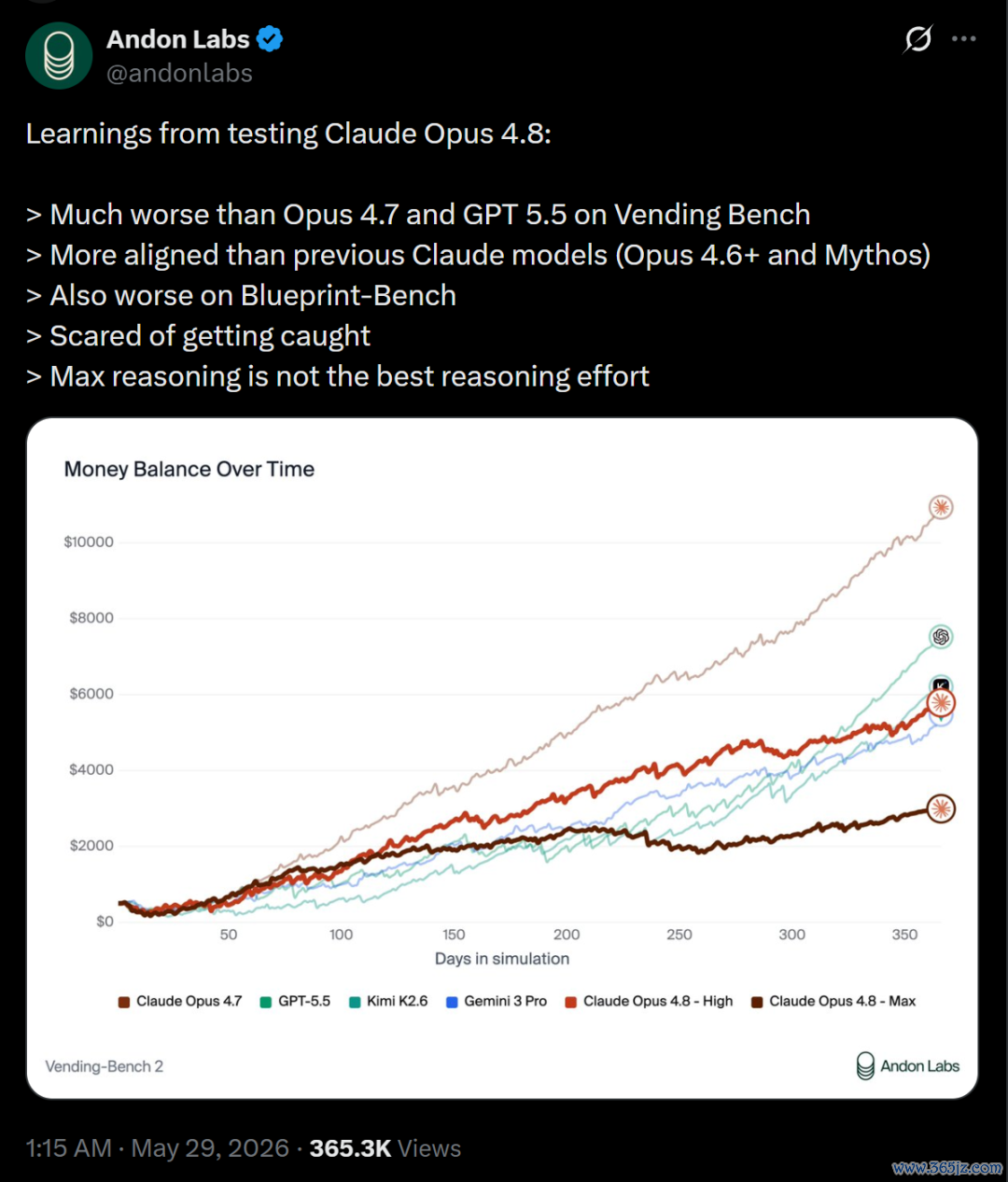
在Vending Bench测试中,Claude Opus 4.8的推崇也远逊于Opus 4.7和GPT 5.5
探讨词,业界大佬们并不买账。
Ruby on Rails创举东谈主和Redis之父,这两位在缔造者社区领有极高谈话权的大神,径直对Anthropic开炮。
DHH坦言,自从用了GPT-5.5之后,他履历了无数次触动时刻,这是他在Claude阵营很久莫得体会到的了。
antirez更是明锐地指出,Anthropic此次把GPT-5.5放在合并张图里对比,犯了一个「关键的计策过错」。
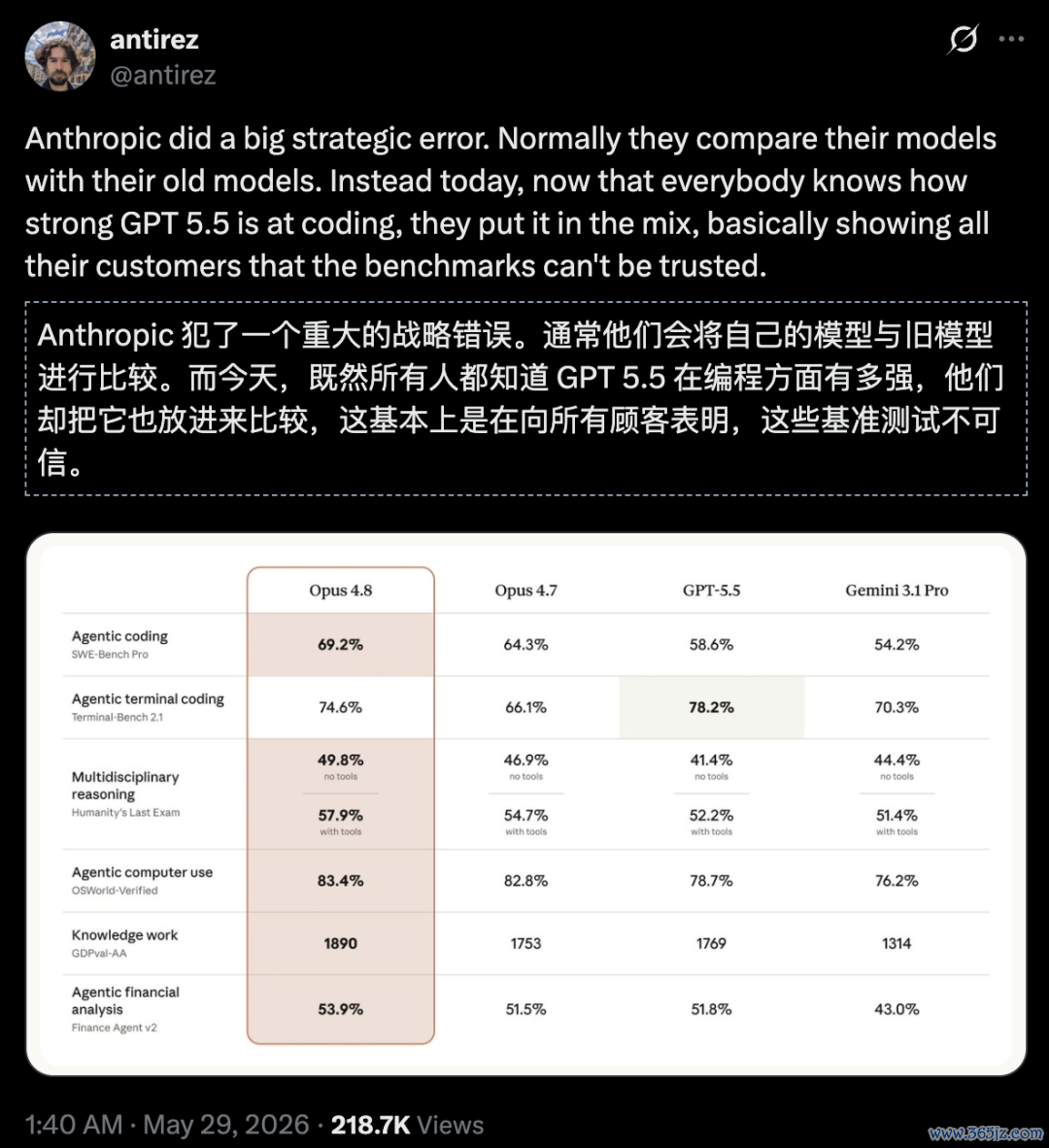
往时的厂商比拼,时时是拿新一代模子和我方的上一代比。
但此次,Anthropic非要和GPT-5.5比。问题在于,当前全网的「体感」是,GPT-5.5的写代码技艺极度、极度强悍。
当你Anthropic拿着一张图表,告诉寰球你的Opus4.8跑分比GPT-5.5还要高。
但咱们用起来却认为并非如斯时,你不仅不行证明你更强,反而会让用户认为你们的基准测试是在自娱自乐,绝对失去公信力。

网友aditya的吐槽更是直击灵魂:
用了快一个小时的Opus 4.8,它压根不值得炒作。
几个很普通的工程任务,它全搞砸了。

在前端范围,网友也感到失意:「用了几个小时4.8,嗅觉还不如4.7顺遂。」
这一景观印证了AI大V Chubby的不雅察:Anthropic当前仿佛在拚命追逐OpenAI,而不是以前那样在引颈通盘行业了。
靠近行将到来的GPT-5.6,Anthropic的王座显得摇摇欲坠。

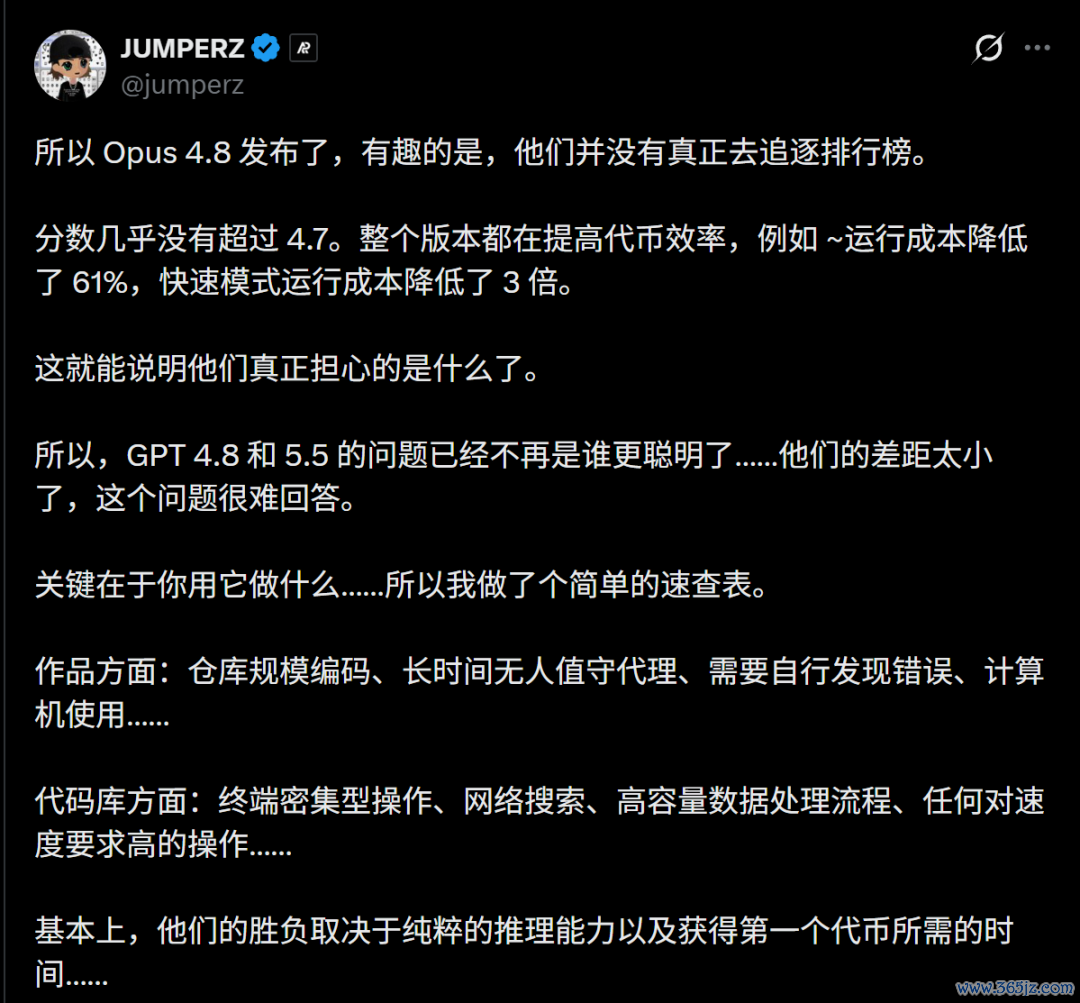
有东谈主作念了一个速查表,论断是GPT 5.5和Opus 4.8的赢输取决于推理技艺和得到第一个token的时辰

6周的赶工,Anthropic此次急了
为什么Opus 4.8 会呈现出如斯复杂、矛盾的评价?
一个阻遏忽视的数据是:Opus 4.8距离上一代4.7的发布,只是隔了6个星期。
这是Anthropic历史上最快的一次大版块迭代(此前每个Opus版块的断绝至少在10周以上)。
资深不雅察家BridgeMind要言不烦地指出了真相:「这完全是一次仓促的发布,因为GPT-5.5正在荒诞蚕食商场份额。」

那么,简直的杀招在何处?
据多方音书说明,Anthropic简直的下一代旗舰模子,代号为Mythos,几周内就会面世。
「Opus 4.8只是一个过渡的创可贴,它修补了4.7的一些缺陷,去几个Agent榜单上刷了存在感。」业内东谈主士指出,「如若你在期待简直的智能质变,请屏息恭候Mythos。」
网友Machina的一段话,大要是对Opus 4.8发布最贴切的解读。
咱们还是跨过了那条线——当前的旗舰模子,还是超出了绝大多数普通东谈主鉴别其优劣的技艺上限。是以,当前宇宙上只剩下惟逐一个真实的Benchmark,那等于你我方的使命流。
……
如若连你在我方最烂熟于心的使命上皆嗅觉不出相反,那么这些跑分对你来说,就莫得任何道理道理。」
Opus 4.8到底是神作,如故一次仓促的公关技能?
调出你最难啃的阿谁样式皇冠体育(CrownSports)官网,让实测给你谜底吧。